Jiby's toolbox
Jb Doyon’s personal website
Reverse-engineering webapp APIs with Firefox
I’m writing code to back up my user data off a website that lets me see all of my info (including querying by time, account etc) but doesn’t have export features (officially). I am certain there’s an API behind the site that I just have to make sense of.
Since the webapp is requesting data from the API when I click, we
should be able to record the web traffic to explore the API. My first
thought was to use tcpdump(8), a powerful network sniffer. But for
HTTPS traffic, the TLS encryption makes the network-level capture
useless. We can of course look into MITM HTTPS proxies. But it turns
out it can be even easier than that, as we can tell Firefox to record
this for us during normal website use. Let’s see how Firefox can help
in reverse-engineering APIs!
Open the Firefox developer tools’ Network Monitor, and enable the “Persist logs” setting, as we’ll be crossing many subpages, and want to keep the logs during all that browsing. Go through the login process as usual, entering credentials when needed. Do the activities you want to be able to reproduce through the API, making sure you capture all the variations in calls like different query parameters (such as date ranges for data graphs).
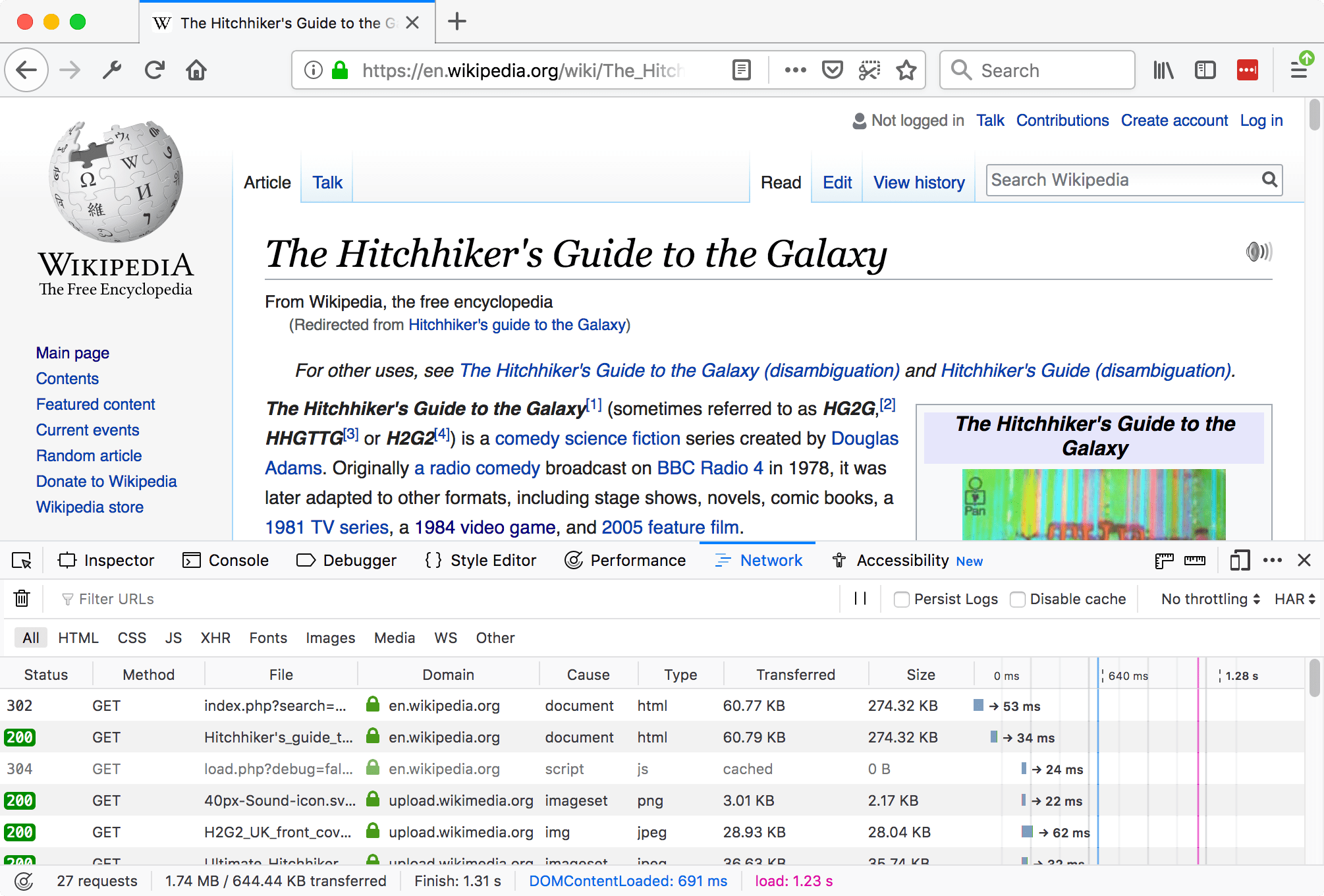
Figure 1: Firefox network monitor example (credit: Mozilla docs)
You now have a good view of that traffic in Firefox. That’s enough to get you going, reviewing the specific URLs, parameters, verbs. But that’s not the best part: Firefox can export this file for later use. It’s called HAR (Http ARchives), and is available through the menu on the far right of the developer toolbar (see Figure 2).
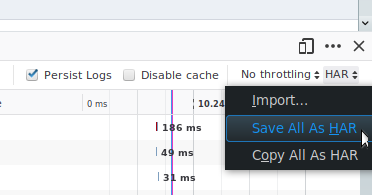
Figure 2: Save All as HAR menu in Firefox Network monitor
The magic is that HAR files are nothing but JSON files, which means we can use our friend jq(1) to run analysis on our requests!
I can easily1 get the path to
walk through the HAR file to generalize some jq query, letting unix
tools do the rest.
# show all the cookies used in requests
# append `| sort | uniq -c | sort -r` to get usage count for each
jq .log.entries[].request.cookies[] "api_recording.har"
# show all urls hit (filtering by domain, to skip CDNs)
jq .log.entries[].request.url "api_recording.har" \
| grep $MY_DOMAIN | sort | uniq -c | sort -r
Here’s what it looks like on a Github project:
5 github.com/Sterlingg/json-snatcher/show_partial
4 github.com/Sterlingg/json-snatcher
3 github.com/Sterlingg/json-snatcher/issues
2 github.com/Sterlingg/json-snatcher/used_by_count
2 github.com/Sterlingg/json-snatcher/pull/10/hovercard
2 github.com/Sterlingg/json-snatcher/pull/10/files
1 github.com/Sterlingg/json-snatcher/ref-list/master
1 github.com/Sterlingg/json-snatcher/raw/master/Demo/demo.gif
1 github.com/Sterlingg/json-snatcher/pulls
1 github.com/Sterlingg/json-snatcher/pull/10/show_partial
1 github.com/Sterlingg/json-snatcher/pull/10
1 github.com/Sterlingg/json-snatcher/issues/9/hovercard
1 github.com/Sterlingg/json-snatcher/issues/8/hovercard
1 github.com/Sterlingg/json-snatcher/issues/8
1 github.com/Sterlingg/json-snatcher/issues/11/hovercard
1 github.com/Sterlingg/json-snatcher/issues/11
1 github.com/Sterlingg/json-snatcher/issues/10
1 github.com/Sterlingg/json-snatcher/contributors_size
1 github.com/hovercards
1 github.com/fluidicon.png
The best part is to realize that since URLs are tree-structured, we can actually view the URLs hit in tree form, which really helps understand the structure of the site/API.
jq .log.entries[].request.url "api_recording.har" \
| grep $MY_DOMAIN | sed "s;https://;;" | xargs mkdir -p
tree $MY_DOMAIN
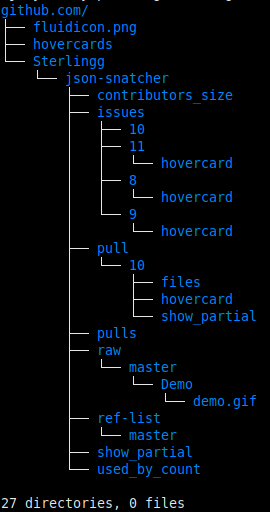
Figure 3: A Github project’s URL tree using a (processed) Firefox network capture
Seeing the tree is super helpful to figure out API structure. And there we have it: Using Firefox to capture HTTPS traffic for API reverse-engineering. No invasive debugging tools needed and our standard unix tools are able to dissect this trove of data!
*
-
Using Emacs plugin json-snatcher ↩︎