Jiby's toolbox
Jb Doyon’s personal website
Git diff from empty commit
In order to troubleshoot a bug in the very early history of a project using git, I needed a way to show the git diff from “nothing” to the first commit. Since git keeps a linked graph of commits, what I wanted was a diff from the commit before the first one. Searching the onlines dug up this answer on StackOverflow, showing that there’s a specific commit hash we can use to diff from “nothing” to the first commit:
git diff 4b825dc642cb6eb9a060e54bf8d69288fbee4904 HEAD
4b825dc642cb6eb9a060e54bf8d69288fbee4904is the id of the “empty tree” in Git and it’s always available in every repository.
A comment by CB Bailey on that answer clarifies:
The id of the empty tree won’t change while git continues to use sha1. You can use
$(printf '' | git hash-object -t tree --stdin)for better readability.
I found that answer fascinating: a magic hash that is the daddy of all repo hashes? It smells of oddities in the internals of git (git’s guts!) that made me curious. So to understand why there’s a magic string that can be used to diff against an empty repo, let’s do some spelunking!
Git objects
From basic git usage, we already know git commits have hashes, and commits make up chains that usually end with branches or tags. We also know that rebasing, changing commit messages, or adding files changes the hash of the commit.
Reading the git internals (git docs), we learn that before having
commits, git tracks things as “objects” by hashing them with SHA-1,
and using the hash as a path under .git/objects/. We discover that
the content of files tracked are objects called “blobs”, and that
“trees” are another type of objects that are made up of a list of
filename + blob hash + file permissions. A single tree object can
represent the entirety of a folder at a point in time, and a tree can
link to another tree, typically subfolders. This is summarized well in
Figure 1.
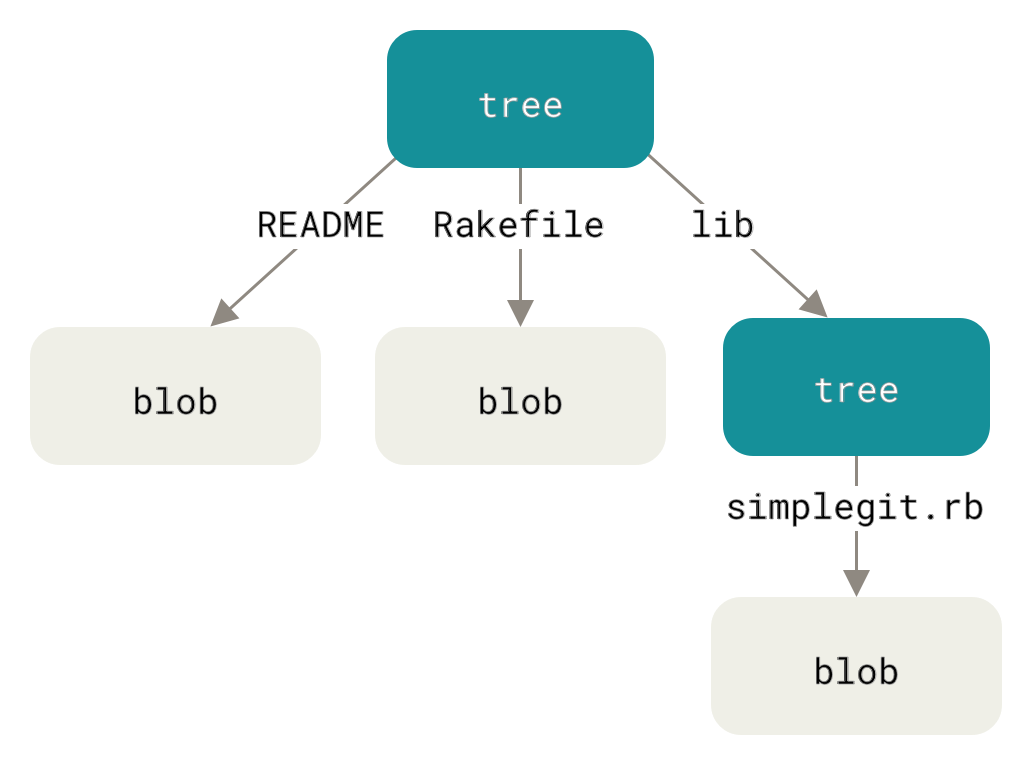
Figure 1: View of a git tree. Credit: git docs
The hash of a blob or tree can be computed with git hash-object,
which brings us one step closer to understanding the command and
hash.
Git commit trees
A commit is another type of object made up of:
- a tree object (of the repo’s root folder after the change we’re committing)
- a link to previous commit (if any)
- a message
- author info (name + email)
- date
This also explains why when we’re changing any of the values above (message, date, tree, author, previous commits) the git commit hash changes, as the commit hash takes all of these into account.
Armed with our new knowledge, let’s revisit the statements made by the StackOverflow community!
So contrary to intuition, it’s not that there’s a commit with no data
that’s the magic source of all data, and that diffing can be done
against that hypothetical commit, but instead (based on the hash-tree
command) it is the hash of an empty tree (no files = the content of
the repo before the first commit), and git diff computes the diff
between “nothing” and our first commit.
The magic of it all boils down to SHA-1 hash itself being computed with known input (empty blob list) that recomputes to the same value every time.
This means as long as git uses SHA-1, this value will stay the same. Interestingly, git is transitioning away from SHA-1, which means sometimes in the future, this magic number won’t work anymore (but the command that computes it will likely still work, as the concept of empty tree object hash is still relevant, just not with the same hashing algorithm).
So, we’ve just used a little curiosity to transform a surprising answer on StackOverflow into knowledge of git internals that can help us reason with the tool. Remember to read the manual, and stay curious!